
This post is by P99 CONF speaker Glauber Costa, founder and CEO of ChiselStrike. It first appeared as an article in ITNext. To hear more from Glauber and many more latency-minded developers, register for P99 CONF today.
I have spent almost the entire last decade in a fairly specialized product company, building high performance I/O systems. I had the opportunity to see storage technology evolve rapidly and decisively. Talking about storage and its developments felt like preaching to the choir.
This year, I have switched jobs. Being at a larger company with engineers from multiple backgrounds I was taken by surprise by the fact that although every one of my peers is certainly extremely bright, most of them carried misconceptions about how to best exploit the performance of modern storage technology leading to suboptimal designs, even if they were aware of the increasing improvements in storage technology.
As I reflected about the causes of this disconnect I realized that a large part of the reason for the persistence of such misconceptions is that if they were to spend the time to validate their assumptions with benchmarks, the data would show that their assumptions are, or at least appear to be, true.
Common examples of such misconceptions include:
- “Well, it is fine to copy memory here and perform this expensive computation because it saves us one I/O operation, which is even more expensive”.
- “I am designing a system that needs to be fast. Therefore it needs to be in memory”.
- “If we split this into multiple files it will be slow because it will generate random I/O patterns. We need to optimize this for sequential access and read from a single file”
- “Direct I/O is very slow. It only works for very specialized applications. If you don’t have your own cache you are doomed”.
Yet if you skim through specs of modern NVMe devices you see commodity devices with latencies in the microseconds range and several GB/s of throughput supporting several hundred thousands random IOPS. So where’s the disconnect?
In this article I will demonstrate that while hardware changed dramatically over the past decade, software APIs have not, or at least not enough. Riddled with memory copies, memory allocations, overly optimistic read ahead caching and all sorts of expensive operations, legacy APIs prevent us from making the most of our modern devices.
In the process of writing this piece I had the immense pleasure of getting early access to one of the next generation Optane devices, from Intel. While they are not common place in the market yet, they certainly represent the crowning of a trend towards faster and faster devices. The numbers you will see throughout this article were obtained using this device.
In the interest of time I will focus this article on reads. Writes have their own unique set of issues — as well as opportunities for improvements that are covered in a different article.
The claims
There are three main problems with traditional file-based APIs:
- They perform a lot of expensive operations because “I/O is expensive”.
When legacy APIs need to read data that is not cached in memory they generate a page fault. Then after the data is ready, an interrupt. Lastly, for a traditional system-call based read you have an extra copy to the user buffer, and for mmap-based operations you will have to update the virtual memory mappings.
None of these operations: page fault, interrupts, copies or virtual memory mapping update are cheap. But years ago they were still ~100 times cheaper than the cost of the I/O itself, making this approach acceptable. This is no longer the case as device latency approaches single-digit microseconds. Those operations are now in the same order of magnitude of the I/O operation itself.
A quick back-of-the-napkin calculation shows that in the worst case, less than half of the total busy cost is the cost of communication with the device per se. That’s not counting all the waste, which brings us to the second problem:
- Read amplification.
Although there are some details I will brush over (like memory used by file descriptors, the various metadata caches in Linux), if modern NVMe support many concurrent operations, there is no reason to believe that reading from many files is more expensive than reading from one. However the aggregate amount of data read certainly matters.
The operating system reads data in page granularity, meaning it can only read at a minimum 4kB at a time. That means if you need to read read 1kB split in two files, 512 bytes each, you are effectively reading 8kB to serve 1kB, wasting 87% of the data read. In practice, the OS will also perform read ahead, with a default setting of 128kB, in anticipation of saving you cycles later when you do need the remaining data. But if you never do, as is often the case for random I/O, then you just read 256kB to serve 1kB and wasted 99% of it.
If you feel tempted to validate my claim that reading from multiple files shouldn’t be fundamentally slower than reading from a single file, you may end up proving yourself right, but only because read amplification increased by a lot the amount of data effectively read.
Since the issue is the OS page cache, what happens if you just open a file with Direct I/O, all else being equal? Unfortunately that likely won’t get faster either. But that’s because of our third and last issue:
- Traditional APIs don’t exploit parallelism.
A file is seen as a sequential stream of bytes, and whether data is in-memory or not is transparent to the reader. Traditional APIs will wait until you touch data that is not resident to issue an I/O operation. The I/O operation may be larger than what the user requested due to read-ahead, but is still just one.
However as fast as modern devices are, they are still slower than the CPU. While the device is waiting for the I/O operation to come back, the CPU is not doing anything.
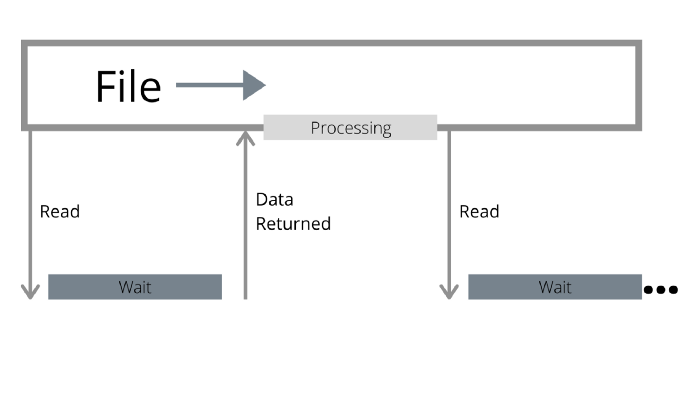
Lack of parallelism in traditional APIs result in the CPUs being idle while they wait for I/O to return.
Using multiple files is a step in the right direction, as it allows more effectively parallelism: while one reader is waiting, another can hopefully proceed. But if you are not careful you just end up amplifying one of the previous problems:
- Multiple files mean multiple read-ahead buffers, increasing the waste factor for random I/O.
- In thread-poll based APIs multiple files mean multiple threads, amplifying the amount of work done per I/O operation.
Not to mention that in many situations that’s not what you want: you may not have that many files to begin with.
Towards better APIs
I have written extensively in the past about how revolutionary io_uring is. But being a fairly low level interface it is really just one piece of the API puzzle. Here’s why:
- I/O dispatched through io_uring will still suffer from most of the problems listed previously if it uses buffered files.
- Direct I/O is full of caveats, and io_uring being a raw interface doesn’t even try (nor should it) to hide these problems: For example, memory must be properly aligned, as well as the positions where you are reading from.
- It is also very low level and raw. For it to be useful you need to accumulate I/O and dispatch in batches. This calls for a policy of when to do it, and some form of event-loop, meaning it works better with a framework that already provides the machinery for that.
To tackle the API issue I have designed Glommio (formerly known as Scipio), a Direct I/O-oriented thread-per-core Rust library. Glommio builds upon io_uring and supports many of its advanced features like registered buffers and poll-based (no interrupts) completions to make Direct I/O shine. For the sake of familiarity Glommio does support buffered files backed by the Linux page cache in a way that resembles the standard Rust APIs (which we will use in this comparison), but it is oriented towards bringing Direct I/O to the limelight.
There are two classes of file in Glommio: Random access files, and Streams.
Random access files take a position as an argument, meaning there is no need to maintain a seek cursor. But more importantly: they don’t take a buffer as a parameter. Instead, they use io_uring’s pre-registered buffer area to allocate a buffer and return to the user. That means no memory mapping, no copying to the user buffer — there is only a copy from the device to the glommio buffer and the user get a reference counted pointer to that. And because we know this is random I/O, there is no need to read more data than what was requested.
Streams, on the other hand, assume that you will eventually run through the entire file so they can afford to use a larger block size and a read-ahead factor.
Streams are designed to be mostly familiar to Rust’s default AsyncRead, so it implements the AsyncRead trait and will still read data to a user buffer. All the benefits of Direct I/O-based scans are still there, but there is a copy between our internal read ahead buffers and the user buffer. That’s a tax on the convenience of using the standard API.
If you need the extra performance, glommio provides an API into the stream that also exposes the raw buffers too, saving the extra copy.
Putting scans to the test
To demonstrate these APIs glommio has an example program that issues I/O with various settings using all those APIs (buffered, Direct I/O, random, sequential) and evaluates their performance.
We start with a file that is around 2.5x the size of memory and start simple by reading it sequentially as a normal buffered file:
Buffered I/O: Scanned 53GB in 56s, 945.14 MB/sThat is certainly not bad considering that this file doesn’t fit in memory, but here the merits are all on Intel Optane’s out-of-this world performance and the io_uring backend. It still has an effective parallelism of one whenever I/O is dispatched and although the OS page size is 4kB, read-ahead allow us to effectively increase the I/O size.
And in fact, should we try to emulate similar parameters using the Direct I/O API (4kB buffers, parallelism of one), the results would be disappointing, “confirming” our suspicion that Direct I/O is indeed, much slower.
Direct I/O: Scanned 53GB in 115s, 463.23 MB/sBut as we discussed, glommio’s Direct I/O file streams can take an explicit read-ahead parameter. If active glommio will issue I/O requests in advance of the position being currently read, to exploit the device’s parallelism.
Glommio’s read-ahead works differently than OS-level read ahead: our goal is to exploit parallelism and not just increase I/O sizes. Instead of consuming the entire read-ahead buffer and only then sending a request for a new batch, glommio dispatches a new request as soon as the contents of a buffer is fully consumed and will always try to keep a fixed number of buffers in-flight, as shown in the image below.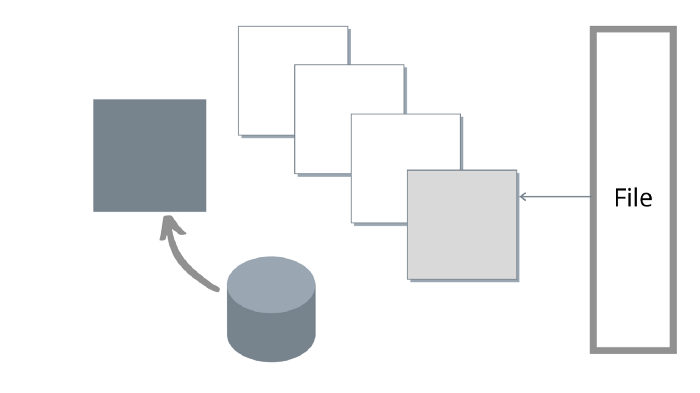
As we exhaust one buffer, another is already being fetched. This has the effect of increasing parallelism and keeping it high.
As initially anticipated, once we exploit parallelism correctly by setting a read-ahead factor Direct I/O is not only on pair with buffered I/O but in fact much faster.
Direct I/O, read ahead: Scanned 53GB in 22s, 2.35 GB/sThis version is still using Rust’s AsyncReadExt interfaces, which forces an extra copy from the glommio buffers to the user buffers.
Using the get_buffer_aligned API gives you raw access to the buffer which avoids that last memory copy. If we use that now in our read test we gain a respectable 4% performance improvement
Direct I/O, glommio API: Scanned 53GB in 21s, 2.45 GB/sThe last step is to increase the buffer size. As this is a sequential scan there is no need for us to be constrained by 4kB buffer sizes, except for the sake of comparison with the OS page cache version.
At this point, let’s summarize all the things that are going on behind the scenes with glommio and io_uring in the next test:
- each I/O request is 512kB in size,
- many (5) of them are kept in flight for parallelism,
- memory is pre-allocated and pre-registered
- no extra copy is performed to a user-buffer
- io_uring is set up for poll mode, meaning there are no memory copies, no interrupts, no context switches.
The results?
Direct I/O, glommio API, large buffer: Scanned 53GB in 7s, 7.29 GB/sThis is more than 7x better than the standard buffered approach. And better yet, the memory utilization was never higher than whatever we set as the read-ahead factor times the buffer size. In this example, 2.5MB.
Random Reads
Scans are notoriously pernicious for the OS page cache. How do we fare with random I/O ? To test that we will read as much as we can in 20s, first restricting ourselves to the first 10% of the memory available (1.65GB)
Buffered I/O: size span of 1.65 GB, for 20s, 693870 IOPSFor Direct I/O:
Direct I/O: size span of 1.65 GB, for 20s, 551547 IOPSDirect I/O is 20% slower than buffered reads. While reading entirely from memory is still faster — which shouldn’t surprise anybody, that’s a far cry from the disaster one would expect. In fact, if we keep in mind that the buffered version is keeping 1.65GB of resident memory to achieve this whereas Direct I/O is only using 80kB (20 x 4kB buffers) this may even be preferable for a particular class of applications that may be better off employing that memory somewhere else.
As any performance engineer would tell you, a good read benchmark needs to read data enough to hit the media. After all, “storage is slow”. So if we now read from the entire file, our buffered performance drops dramatically by 65%.
Buffered I/O: size span of 53.69 GB, for 20s, 237858 IOPSWhile Direct I/O, as expected, has the same performance and the same memory utilization irrespectively of the amount of data read.
Direct I/O: size span of 53.69 GB, for 20s, 547479 IOPSIf the larger scans are our comparison point, then Direct I/O is 2.3x faster, not slower, than buffered files.
Conclusion
Modern NVMe devices change the nature of how to best perform I/O in stateful applications. This trend has been going on for a while but has been so far masked by the fact that the APIs, especially the higher level ones, haven’t evolved to match what has been happening in the device — and more recently Linux Kernel layers. With the right set of APIs, Direct I/O is the new black.
Newer devices like the newest generation of the Intel Optane just seal the deal. There is no scenario in which standard buffered I/O is undisputedly better than Direct I/O.
For scans the performance of well-tailored Direct I/O-based APIs is simply far superior. And while Buffered I/O standard APIs performed 20% faster for random reads that fully fit in memory, that comes at the cost of 200x more memory utilization making the trade offs not a clear cut.
Applications that do need the extra performance will still want to cache some of those results, and providing an easy way to integrate specialized caches for usage with Direct I/O is in the works for glommio.

